Opus 4.7이 claude-code 단독으로 로봇개 프로그래밍 5개 과제를 평균 12분 7초에 끝냈다 — 1년 전 같은 과제를 푼 사내 최고 인간 팀(Opus 4.1 보조)이 쓴 181분 대비 약 19배 빠르고, 코드량은 10,309줄에서 1,045줄로 약 10분의 1로 줄었다. 단, 비치볼을 출발점으로 정확히 되돌리는 closed-loop 제어는 여전히 실패.
한눈에4개 공통 과제 9분 35초 vs Team Claude 181분(약 18.9배) vs Team Claude-less 361분(약 37.7배)Opus 4.7 코드 1,045줄, Team Claude 10,309줄 — 첫 시도에 작동3회 반복 분산 낮음, 하지만 closed-loop 비치볼 회수는 실패
실무자: 범용 LLM의 인터페이스 탐색·첫시도 코드 정확도가 임계점을 넘었다는 신호 — 새 SDK·하드웨어 통합 작업의 시간 분포가 바뀐다. 리더: 의도한 로보틱스 학습이 아닌 일반 스케일링의 spillover. 비용·R&D 시간 가정의 재검토가 필요하다.
Anthropic frontier-red-team이 Project Fetch: Phase Two를 6월 18일 공개했다. 이는 2025년 11월 1단계 발표의 종단 후속 — 같은 4족 로봇·같은 과제를 약 10개월 뒤 claude-opus-4-7로 다시 측정한 실험이다.
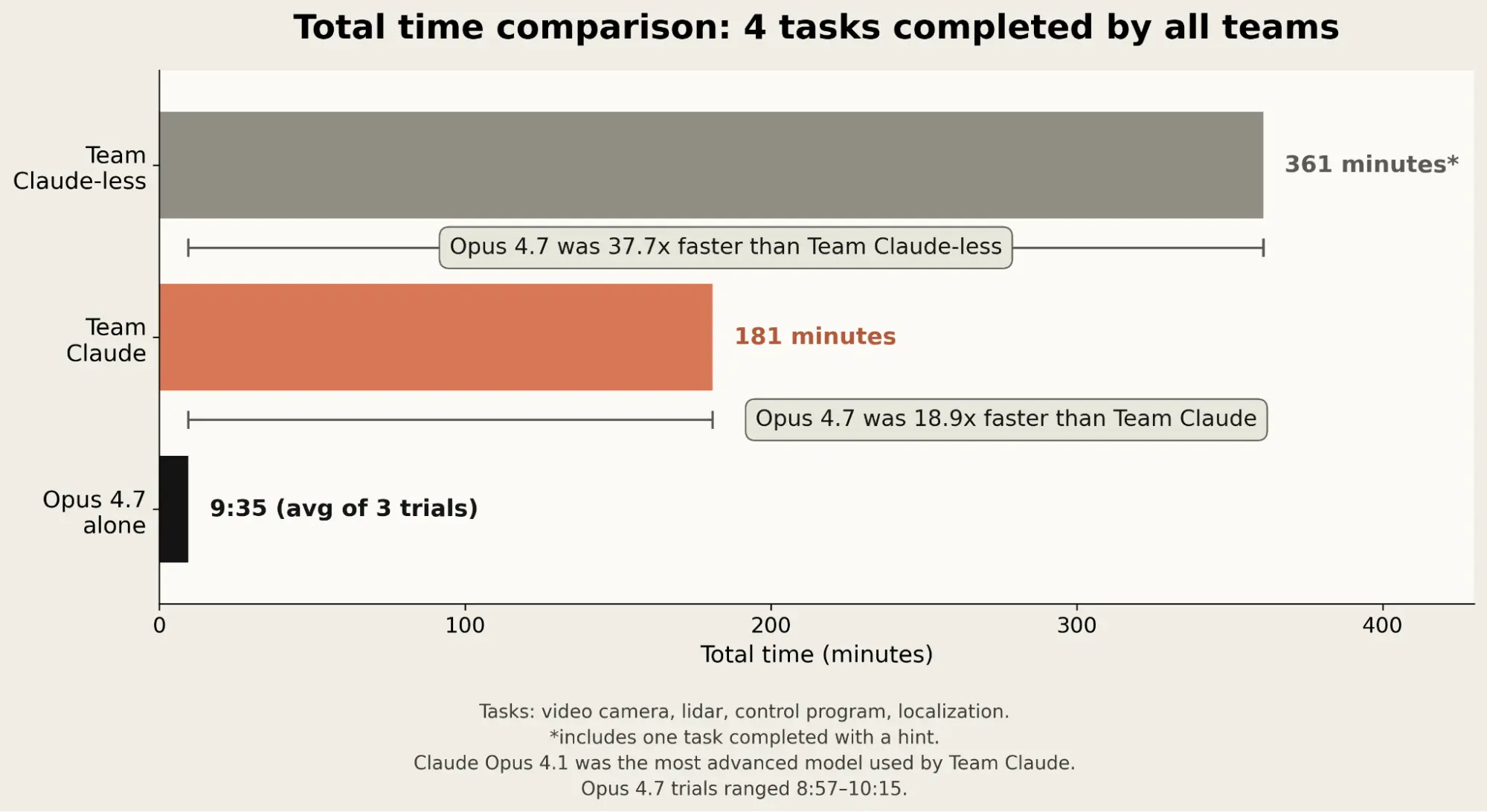
이미지: 4개 공통 과제 총 소요 시간 비교. 출처: Project Fetch: Phase two
무엇이 일어났나
Phase 1(2025.08)은 로보틱스 비전공 Anthropic 직원 8명을 4명씩 두 팀으로 무작위 배정했다. Team Claude는 당시 최신 Opus 4.1을 도구로, Team Claude-less는 인터넷과 머리만 썼다. 과제는 (1) 제조사 컨트롤러 조작, (2) 노트북-로봇 영상/라이다 연결, (3) 수동 제어 프로그램, (4) 공간 경로 추적, (5) 비치볼 인식, (6) 자율적 공 회수.
Phase 2(2026.04~06)에서는 claude-opus-4-7이 claude-code 안에서 'adaptive thinking, maximum effort'로 단독 수행. 사람은 (1) 노트북-로봇 물리 연결, (2) 초기 프롬프트 입력, (3) 명령/단계 진행 승인 클릭만 했다. 컨트롤러 단계는 자동화 대상에서 제외, 나머지 5개 과제를 3회 반복했다.
로봇 기종은 본문에 명시되지 않았으나, TechBuzz.ai와 Forklog 보도는 unitree-go2 (~$16,900)로 특정했다.
숫자로 보기
- 4개 공통 과제 누적 시간: Team Claude-less 361분 → Team Claude 181분 → Opus 4.7 9분 35초
- 속도 우위: Team Claude 대비 18.9배, Team Claude-less 대비 37.7배
- 5개 자동화 과제 평균(Opus 4.7): 12분 7초
- 코드 라인: Team Claude 10,309 / Team Claude-less 1,136 / Opus 4.7 1,045
- 반복 안정성: 3회 trial 내 과제별 분산 낮음. 단, 비치볼 검출 한 trial이 outlier — 구버전 객체 탐지 알고리즘 default 선택 때문
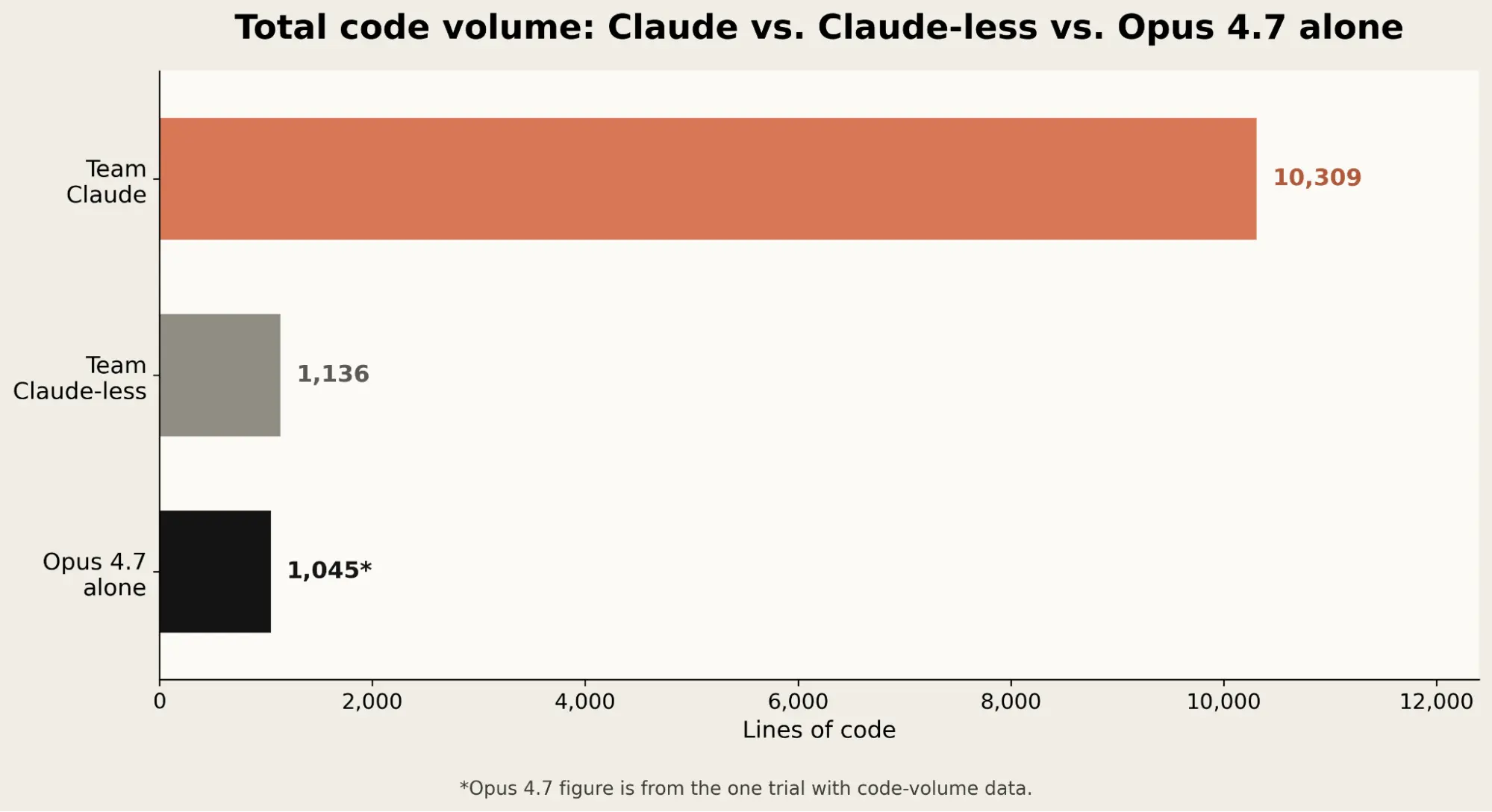
이미지: 총 코드 라인 — Team Claude 10,309, Team Claude-less 1,136, Opus 4.7 1,045. 출처: Project Fetch: Phase two
왜 중요한가
엔지니어 입장에서 핵심은 두 가지다.
첫째, 인터페이스 결정 속도. 인간 팀이 가장 오래 막혔던 단계는 "로봇의 어느 SDK·토픽·라이브러리를 쓸 것인가"를 고르는 단계였다. Opus 4.7은 그 선택을 즉시 했고, 대부분의 코드가 첫 실행에서 작동했다. 새 하드웨어·외부 API와 통합할 때의 작업 시간 곡선이 바뀐다는 뜻이다.
둘째, 코드량 10배 절감. Team Claude의 10,309줄은 LLM에게 매번 시키고 디버깅하며 누적된 결과다. Opus 4.7의 1,045줄은 더 좋은 추상화를 한 번에 골랐기 때문이다. "AI 보조 = 코드 더 많이 나옴"이라는 휴리스틱은 끝났다.
본문은 또한 "이 진전은 모델의 로보틱스 능력을 의도적으로 개선한 결과가 아니라, 훨씬 더 일반적인 스케일링에서 emergent하게 나온 것"이라고 명시한다. 코딩·비전 능력 향상이 로봇 인터페이스 작업으로 transfer됐다는 주장이다.
누가 이득, 누가 손해
이득: 사내에 로보틱스 전담 인력이 없는 팀이 unitree-go2 같은 저가 4족 로봇과 claude-code만으로 프로토타입을 만들 수 있다. R&D 초기 비용 가정이 깨진다.
손해: SDK 연결·센서 통합을 단가 작업으로 받던 외주 시장은 가격 압박. 또 폐쇄형 API에 의존하던 로봇 보조 미들웨어 스타트업은 구분 가치가 줄어든다.
더 깊이
이 결과의 안전·정책적 함의는 분명하다. Anthropic은 "모델이 인간을 돕는다 → 인간이 모델을 돕는다 → 모델이 단독으로 한다" 곡선을 사이버보안 평가에서 관찰해왔고, 본문은 같은 패턴이 물리 세계로 옮겨오고 있다고 주장한다. 본문 그대로 옮기면: "모델이 자기 소프트웨어 도구를 만든다는 게 얼마 전엔 황당했지만 지금 일어나고 있다. 하드웨어에서도 같은 궤적을 배제하기는 어리석을 것이다."
그러나 한 영역에서 Opus 4.7은 여전히 실패했다 — closed-loop-control. 비치볼을 정확히 출발점으로 보내려면 오차를 감지하고 직전 명령과 연결하고 다음 입력을 미세 조정해야 한다. 인간이 짧은 시행착오 끝에 학습하는 운동 직관을 모델은 아직 못한다. 단, Anthropic은 "Phase 1 참가자보다 로보틱스 경험 많은 사내 연구자 한 명은 같은 모델로 자율 fetching을 성공시켰다. 더 많은 시간과 스캐폴딩만 주면 가능할 것"이라고 부연했다.
아직 알 수 없는 것
- n=3 trial은 분산 주장에 박하다. 외부 재현 데이터 0건.
- 비교 기준이 로보틱스 비전공 직원이다. 진짜 로보틱스 엔지니어 vs Opus 4.7 비교는 빠짐.
- Anthropic은 Opus 4.7이 사용한 SDK·비전 스택·fallback 객체 탐지 알고리즘의 구체 이름을 공개하지 않았다.
- "scaffolding을 더 주면 fetching도 된다"는 부연은 별도 검증 없이 본문에만 등장.
- 본 실험이 Anthropic Responsible Scaling Policy의 어느 임계 평가 항목에 매핑되는지 명시 안 됨.
5분 실습 (쉬움 · 5분)
아래 "5분 실험" 섹션의 시나리오를 본인이 안 써본 SDK에 직접 적용해보라. Phase 2의 핵심 주장인 "첫 시도 코드 정확도"가 본인 환경에서도 재현되는지가 가장 짧은 검증이다.
더 읽어보기
- Project Fetch: Phase two · 2026.06.18 · 본 실험 1차 자료
- Project Fetch: Can Claude train a robot dog? · 2025.11.12 · Phase 1
- Introducing Claude Opus 4.7 · 2026.04.16 · 모델 capability
- Benzinga: Anthropic Makes 'Fetch' Happen · 시장 반응
- FourWeekMBA: 20x faster robotics · 외부 분석
- TechBuzz.ai: Claude AI Successfully Controls Robot Dog · 로봇 기종 특정